Image restoration using deep learning
The task of image restoration is to restore a clean image from its degraded version. We propose image restoration methods based on deep neural networks.

Vision and Language
We study methods to understand the visual information on an image using natural language. For example, we proposed a method that takes an image and a natural language question about the image and provides an accurate natural language answer as the output (a.k.a VQA). Other than VQA, we also study other vision and language tasks such as visual dialog and image captioning.

Classification of objects using deformed images is a challenge that has been studied extensively in computer vision and pattern recognition in the last decades. While convolutional neural networks (CNNs) have achieved impressive progress in object classification and recognition in some benchmark datasets, recent works show that their performance is severely degraded for classification and recognition using deformed images. Our works focus on improvement of robustness of learned deep feature representations to deformations by constructing CNNs with new essences.

How can we discover visual attributes of massive images and texts uploaded on the web? We propose an approach for automatically discovering their visual attributes using convolutional neural networks.
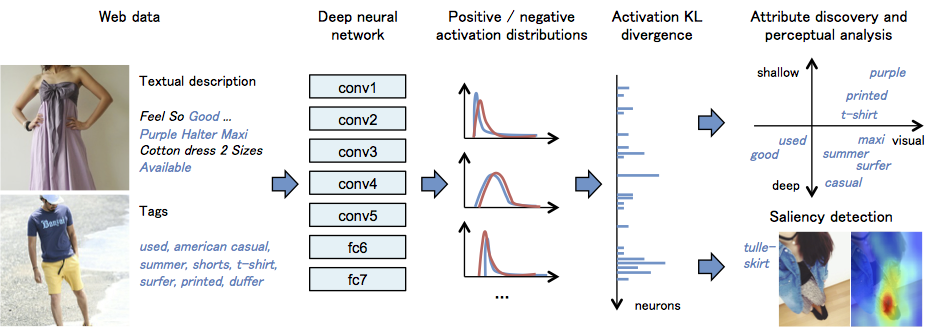
 We are studying methods for recognizing the surface qualities of an object from its single image. By surface qualities we mean a variety of sensations that humans receive for the surface of an object, such as smoothness/roughness, glossiness, and bumpiness. We believe that the surface quality of an object can be represented by a set of such attributes, which form a comprehensive concept (called Sitsukan in Japanese) in the human brain in a mutually connected manner.
We are studying methods for recognizing the surface qualities of an object from its single image. By surface qualities we mean a variety of sensations that humans receive for the surface of an object, such as smoothness/roughness, glossiness, and bumpiness. We believe that the surface quality of an object can be represented by a set of such attributes, which form a comprehensive concept (called Sitsukan in Japanese) in the human brain in a mutually connected manner.
This study takes a machine-vision approach to this problem of estimating various surface quality attributes from an image.
We propose a deep learning model that generates descriptions about product images on an e-commerce site. The model consists of convolutional neural networks and recurrent neural networks. We first extract clean, useful training data set from noisy data on the web using natural language processing techniques. Then, we trained the model with product images and their titles. This project is a collaboration with Communication Science Laboratory at Tohoku university.

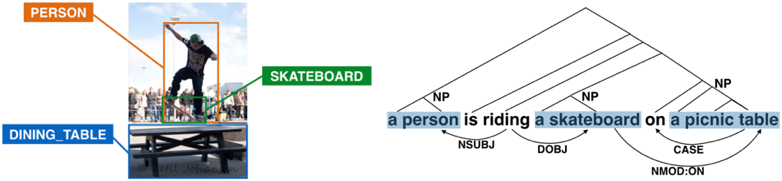
How can we represent relations between objects in images using languare? Recently, deep neural networks achieved significant performances on various object recognition tasks. We focuse on relations of such objects and propose a model for representing the relations by language. This project is a collaboration with Communication Science Laboratory at Tohoku University.
Convolutional neural networks (CNNs) were developed with some inspirations from neuroscientific insights about the brain. Recently, several studies investigated the relationship between neural acitivities in the primate brain and internal representations in CNNs. We are working on the following problems for understanding and developing more biologically-plausible vision models:
1. Relationship between brain waves in the primate visual cortex and internal representation in CNNs
2. Deep learning model for decoding various visual features from neural activities in the brain.
This project is a collaboration with Hasegawa Lab at Department of Physiology, Niigata University Graduate School of Medical and Dental Sciences.
Since right after the occurrence of the Great East Japan Earthquake on March 11th, 2011, we have been periodically capturing the images of the disaster areas in the north-eastern Japan coastline by using a vehicle having a camera on its roof. The motivation behind the periodic image capturing is to archive not only the damages of the areas but also the process of their month-by-month recovery or year-by-year reconstruction. The image data thus being obtained amount to about 40 terabytes as of today. Although they can be used as they are, i.e., by viewing the images one-by-one in a manner similar to Google Street View, we think that the data contain rich information, often in an invisible form, which can be used in many more ways. Thus, in parallel with the archiving activity, we have been studying the method for extracting such useful information from the image data by using all sorts of computer vision techniques. The goal is to visualize what extent and type of damages the earthquake and tsunami gave each city and how damaged cities change their shapes as their recovery and reconstruction proceed.
Understanding Deep Convolutional Neural Networks
It has been recently reported that convolutional networks show good performances in many image recognition tasks. They significantly outperform the previous approaches that are not based on neural networks particularly for object category recognition. These performances are arguably owing to their ability of discovering better image features for recognition tasks through learning, resulting in the acquisition of better internal representations of the inputs. However, in spite of the good performances, it remains an open question why the convolutional networks work so well and/or how they can learn such good representations. In this study, we conjecture ... Read more...
We have been recording the images of the coastal areas damaged by Greate East Japan Earthquake of 11 March, 2011. The following video is an example of our archive, which is captured by an omni-directional camera mounted on a vehicle. We aim at recording not only the damages right after the earthquake but the process of recovery and reconstruction since then. For this purpose, we have been peridoically acquiring the images of the same areas. We are also developing methods for creating spatio-temporal models of these areas from the image data thus recorded, aiming at visualizing the damages as well as the recovery/reconstruction processes.
We have developed a variety of image-media systems by integrating projectors with cameras. The following video is a demonstration of calibrating a multi-projector display, which makes it possible to display a single high-resolution image with multiple projectors. All you have to do to calibrate the system is to acquire a single image with a hand-held camera from an arbitrary point in space.
We have developed a method for measuring the shape of an object by integration of geometry-based and photometry-based methods for shape measurement. A major feature is that it does not need precise knowledge of surface reflectance of the object surface even though it uses photometric stereo.
We have developed a method for tracking a plane moving in space, that is, estimating its position and shape in a video image captured by a camera. In particular, our method can track a plane with higher accuracy than earlier methods when the plane has an oblique angle toward the camera or when it moves to a distant place from the camera. The following video shows a performance comparison among three tracking methods including ours: the two in the upper row are the previous state-of-the-art and the one in the lower row is ours.
Read more...